In the previous blogs, we discussed how to find the corners using algorithms such as Harris Corner, Shi-Tomasi, etc. If you notice, the detected corners had integer coordinates such as (17,34), etc. This generally works if we were extracting these features for recognition purposes but when it comes to some geometrical measurements we need more precise corner locations such as real-valued coordinates (17.35,34.67). So, in this blog, we will see how to refine the corner locations (detected using Harris or Shi-Tomasi Detector) with sub-pixel accuracy.
OpenCV
OpenCV provides a builtin function cv2.cornerSubPix() that finds the sub-pixel accurate location of the corners. Below is the syntax of this
|
1 |
cv2.cornerSubPix(image, corners, winSize, zeroZone, criteria) |
This function uses the dot product trick and iteratively refines the corner locations till the termination criteria is reaches. Let’s understand this in somewhat more detail.
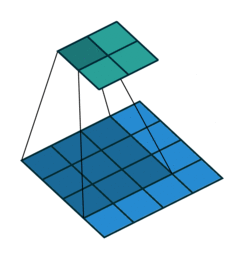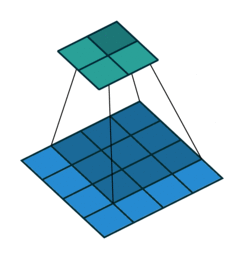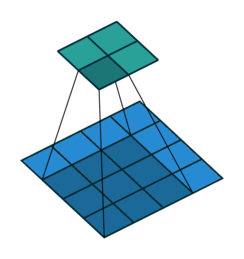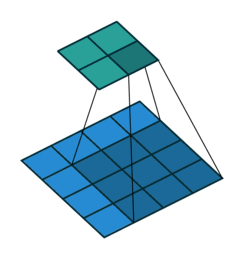
Consider the image shown below. Suppose, q is the starting corner location and p is the point located within the neighborhood of q.

Clearly, the dot product between the gradient at p and the vector q-p is 0. For instance, for the first case because p0 lies in a flat region, so the gradient is 0 and hence the dot product. For the second case, the vector q-p1 lies on the edge and we know that the gradient is perpendicular to the edge so the dot product is 0.
Similarly, we take other points in the neighborhood of q (defined by the winSize parameter) and set the dot product of gradient at that point and the vector to 0 as we did above. Doing so we will get a system of equations. These equations form a linear system that can be solved by the inversion of a single autocorrelation matrix. But this matrix is not always invertible owing to small eigenvalues arising from the pixels very close to q. So, we simply reject the pixels in the immediate neighborhood of q (defined by the zeroZone parameter).
This will give us the new location for q. Now, this will become our starting corner location. Keep iterating until the user-specified termination criterion is reached. I hope you understood this.
Now, let’s take a look at the arguments that this function accepts.
- image: Input single-channel, 8-bit grayscale or float image
- corners: Array that holds the initial approximate location of corners
- winSize: Size of the neighborhood where it searches for corners. This is the Half of the side length of the search window. For example, if winSize=Size(5,5) , then a (5∗2+1)×(5∗2+1)=11×11 search window is used
- zeroZone: This is the half of the neighborhood size we want to reject. If you don’t want to reject anything pass (-1.-1)
- criteria: Termination criteria. You can either stop it after a specified number of iterations or a certain accuracy is achieved, or whichever occurs first.

For instance, in the above image the red pixel is the initial corner. The winSize is (3,3) and the zeroZone is (1,1). So, only the green pixels have been considered for generating equations while the grey pixels have been rejected.
Now, let’s take the below image and see how to do this using OpenCV-Python

Steps
- Load the image and find the corners using Harris Corner Detector as we did in the previous blog. You can use Shi-Tomasi detector also
- Now, there may be a bunch of pixels at the corner, so we take their centroids
- Then, we define the stopping criteria and refine the corners to subpixel accuracy using the cv2.cornerSubPix()
- Finally, we used red color to mark Harris corners and green color to mark refined corners
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import numpy as np import cv2 # Load the image and convert to grayscale img = cv2.imread('D:/downloads/contracing.png') gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) # find Harris corners as we did in the previous blog gray = np.float32(gray) dst = cv2.cornerHarris(gray,2,3,0.04) dst = cv2.dilate(dst,None) ret, dst = cv2.threshold(dst,0.01*dst.max(),255,0) dst = np.uint8(dst) # find centroids ret, labels, stats, centroids = cv2.connectedComponentsWithStats(dst) # define the criteria to stop. We stop it after a specified number of iterations # or a certain accuracy is achieved, whichever occurs first. criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.001) # Refine the corners using cv2.cornerSubPix() corners = cv2.cornerSubPix(gray,np.float32(centroids),(5,5),(-1,-1),criteria) # To display, first convert the centroids and corners to integer centroids = np.int0(centroids) corners = np.int0(corners) # then i have used red color to mark Harris Corners # and green color to mark refined corners img[centroids[:,1], centroids[:,0]]=[0,0,255] img[corners[:,1], corners[:,0]] = [0,255,0] # Write the image at the desired location cv2.imwrite('D:/downloads/subpixel5.png',img) |
Below are the results of this. For visualization, I have shown the zoomed in version on the right.

Applications
Subpixel corner locations are a common measurement used in camera calibration or when tracking to reconstruct the camera’s path or the three-dimensional structure of a tracked object or used in some algorithms such as SIFT (discussed in the next blog), etc.
That’s all for this blog. Hope you enjoy reading.
If you have any doubts/suggestions please feel free to ask and I will do my best to help or improve myself. Goodbye until next time.
{kind=link}