Isn’t this an interesting topic? If you have worked with image classification problems( e.g. classifying cats and dogs) or image generation problems( e.g. GANs, autoencoders), surely you have encountered with convolution and deconvolution layer. But what if someone says a deconvolution layer is same as a convolution layer.
This paper has proposed an efficient subpixel convolution layer which works same as a deconvolution layer. To understand this, lets first understand convolution layer , transposed convolution layer and sub pixel convolution layer.
Convolution Layer
In every convolution neural network, convolution layer is the most important part. A convolution layer is consist of numbers of independent filters which convolve independently with input and produce output for the next layer. Let’s see how a filter convolve with the input.
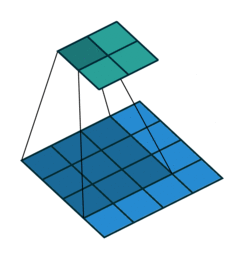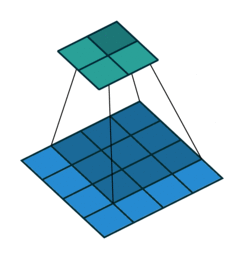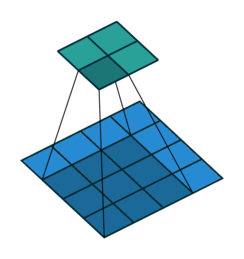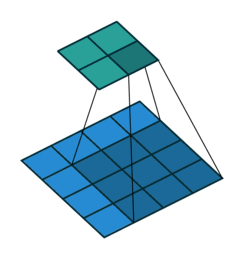
Transposed and sub pixel Convolution Layer
Transposed convolution is the inverse operation of convolution. In convolution layer, you try to extract useful features from input while in transposed convolution, you try to add some useful features to upscale an image. Transposed convolution has learnable features which are learnt using backpropogation. Lets see how to do a transposed convolution visually.
Similarly, a subpixel convolution is also used for upsampling an image. It uses fractional strides( input is padded with in-between zero pixels) to an input and outputs an upsampled image. Let’s see visually.
An efficient sub pixel convolution Layer
In this paper authors have proposed that upsampling using deconvolution layer isn’t really necessary. So they came up with this Idea. Instead of putting in between zero pixels in the input image, they do more convolution in lower resolution image and then apply periodic shuffling to produce an upscaled image.
r denotes the up scaling ratio
Authors have illustrated that deconvolution layer with kernel size of (o, i,
In the above figure,
Implementation
I have also implemented an autoencoder(using MNIST dataset) with efficient subpixel convolution layer. Let’s see the
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
def _phase_shift(I, r): # defines periodical shuffling to upscale image input_shape = tf.shape(I) bsize = input_shape[0] a = input_shape[1] b = input_shape[2] c = tf.cast(input_shape[3]/(r ** 2),tf.int32) shape = tf.stack([bsize,a,b,r,r,c]) input_shape_as_numbers = I.get_shape() X = tf.reshape(tensor=I, shape=shape) X = tf.transpose(X, (0, 1, 2, 4, 3,5)) X = tf.split(X, input_shape_as_numbers[1], axis=1) X = tf.concat([tf.squeeze(x) for x in X], axis=2) X = tf.split(X,input_shape_as_numbers[2], axis=1) X = tf.concat([tf.squeeze(x) for x in X], axis=2) return tf.reshape(X, (bsize, a*r, b*r, c)) def PS(input_shape, r, name, color=False): def subpixel_shape(input_shape): dims = [input_shape[0], input_shape[1] * r, input_shape[2] * r, int(input_shape[3] / (r ** 2))] output_shape = tuple(dims) return output_shape def subpixel(x): if color: Xc = tf.split(3, 3, X) X = tf.concat(3, [_phase_shift(x, r) for x in Xc]) else: x_upsampled = _phase_shift(x, r) return x_upsampled return Lambda(subpixel, output_shape=subpixel_shape, name=name) # encoder layers encoder_inputs = Input(shape = (28,28,1)) conv1 = Conv2D(16, (3,3), activation = 'relu', padding = "SAME")(encoder_inputs) pool1 = MaxPooling2D(pool_size = (2,2), strides = 2)(conv1) conv2 = Conv2D(32, (3,3), activation = 'relu', padding = "SAME")(pool1) pool2 = MaxPooling2D(pool_size = (2,2), strides = 2)(conv2) flat = Flatten()(pool2) #decoder layer dense_layer_d = Dense(7*7*32, activation = 'relu')(enocder_outputs) output_from_d = Reshape((7,7,32))(dense_layer_d) # convolution then periodical shuffling to upscale image sub_up = Conv2D(128, (2,2), activation = 'relu', padding = "SAME")(output_from_d) upSampled_1 = PS(sub_up.shape, 2, name = 'subpixel1', color=False)(sub_up) output_from_upSampled_1 = Reshape((14,14,32))(upSampled_1) # convolution then periodical shuffling to upscale image sub_up_2 = Conv2D(4, (2,2), activation = 'relu', padding = "SAME")(output_from_upSampled_1) output = PS(sub_up_2.shape, 2, name = 'subpixel2', color=False)(sub_up_2) autoencoder = Model(encoder_inputs, output) # training of model m = 256 n_epoch = 25 autoencoder.compile(optimizer='adam', loss='mse') autoencoder.fit(output_X_train,output_X_train, epochs=n_epoch, batch_size=m, shuffle=True) |
The above periodic shuffling code is given by this
This type of subpixel convolution layers can be very helpful in problems like image generation( autoencoders, GANs), image enhancement(super resolution). Also there is more to find out what can this efficient subpixel convolution layer offers.
Now, you might have got some feeling about efficient subpixel convolution layer. Hope you enjoy reading.
If you have any doubt/suggestion please feel free to ask and I will do my best to help or improve myself. Good-bye until next time.
Referenced Research Paper : Is the deconvolution layer the same as a convolutional layer?
Referenced Gitub Link : Subpixel