In the previous blog, we have seen how to create training and validation dataset for our recognition model( Download and preprocess ). In this blog, we will create our model architecture and train it with the preprocessed data.
Model = CNN + RNN + CTC loss
Our model consists of three parts:
- The convolutional neural network to extract features from the image
- Recurrent neural network to predict sequential output per time-step
- CTC loss function which is transcription layer used to predict output for each time step.
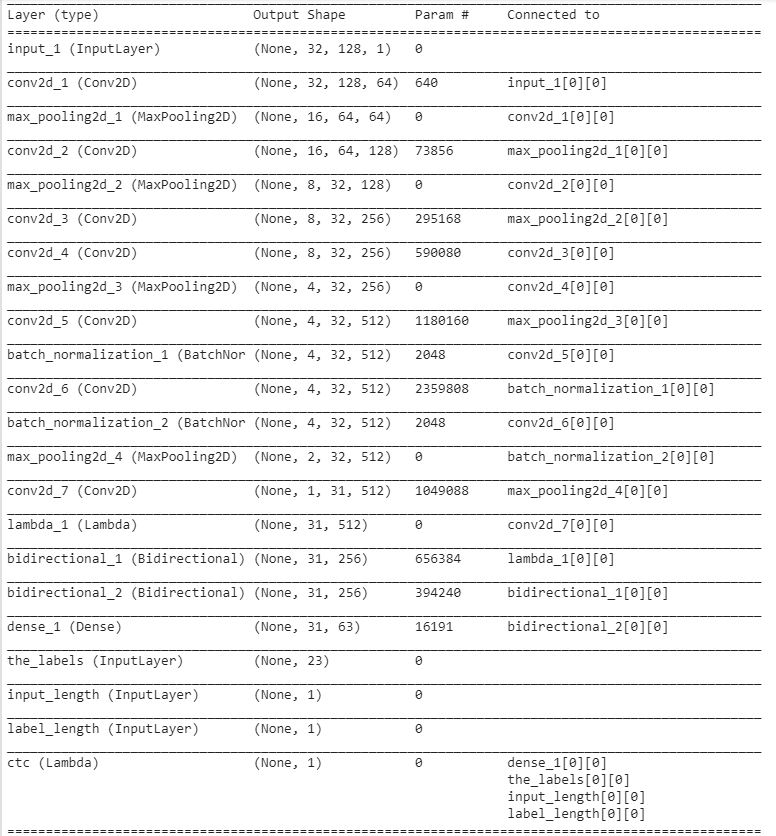
Model Architecture
Here is the model architecture that we used:

This network architecture is inspired by this paper. Let’s see the steps that we used to create the architecture:
- Input shape for our architecture having an input image of height 32 and width 128.
- Here we used seven convolution layers of which 6 are having kernel size (3,3) and the last one is of size (2.2). And the number of filters is increased from 64 to 512 layer by layer.
- Two max-pooling layers are added with size (2,2) and then two max-pooling layers of size (2,1) are added to extract features with a larger width to predict long texts.
- Also, we used batch normalization layers after fifth and sixth convolution layers which accelerates the training process.
- Then we used a lambda function to squeeze the output from conv layer and make it compatible with LSTM layer.
- Then used two Bidirectional LSTM layers each of which has 128 units. This RNN layer gives the output of size (batch_size, 31, 63). Where 63 is the total number of output classes including blank character.
Let’s see the code for this architecture:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# input with shape of height=32 and width=128 inputs = Input(shape=(32,128,1)) # convolution layer with kernel size (3,3) conv_1 = Conv2D(64, (3,3), activation = 'relu', padding='same')(inputs) # poolig layer with kernel size (2,2) pool_1 = MaxPool2D(pool_size=(2, 2), strides=2)(conv_1) conv_2 = Conv2D(128, (3,3), activation = 'relu', padding='same')(pool_1) pool_2 = MaxPool2D(pool_size=(2, 2), strides=2)(conv_2) conv_3 = Conv2D(256, (3,3), activation = 'relu', padding='same')(pool_2) conv_4 = Conv2D(256, (3,3), activation = 'relu', padding='same')(conv_3) # poolig layer with kernel size (2,1) pool_4 = MaxPool2D(pool_size=(2, 1))(conv_4) conv_5 = Conv2D(512, (3,3), activation = 'relu', padding='same')(pool_4) # Batch normalization layer batch_norm_5 = BatchNormalization()(conv_5) conv_6 = Conv2D(512, (3,3), activation = 'relu', padding='same')(batch_norm_5) batch_norm_6 = BatchNormalization()(conv_6) pool_6 = MaxPool2D(pool_size=(2, 1))(batch_norm_6) conv_7 = Conv2D(512, (2,2), activation = 'relu')(pool_6) squeezed = Lambda(lambda x: K.squeeze(x, 1))(conv_7) # bidirectional LSTM layers with units=128 blstm_1 = Bidirectional(LSTM(128, return_sequences=True, dropout = 0.2))(squeezed) blstm_2 = Bidirectional(LSTM(128, return_sequences=True, dropout = 0.2))(blstm_1) outputs = Dense(len(char_list)+1, activation = 'softmax')(blstm_2) act_model = Model(inputs, outputs) |
Loss Function
Now we have prepared model architecture, the next thing is to choose a loss function. In this text recognition problem, we will use the CTC loss function.
CTC loss is very helpful in text recognition problems. It helps us to prevent annotating each time step and help us to get rid of the problem where a single character can span multiple time step which needs further processing if we do not use CTC. If you want to know more about CTC( Connectionist Temporal Classification ) please follow this blog.
Note: For more details on the Optical Character Recognition , please refer to the Mastering OCR using Deep Learning and OpenCV-Python course.
A CTC loss function requires four arguments to compute the loss, predicted outputs, ground truth labels, input sequence length to LSTM and ground truth label length. To get this we need to create a custom loss function and then pass it to the model. To make it compatible with our model, we will create a model which takes these four inputs and outputs the loss. This model will be used for training and for testing we will use the model that we have created earlier “act_model”. Let’s see the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
labels = Input(name='the_labels', shape=[max_label_len], dtype='float32') input_length = Input(name='input_length', shape=[1], dtype='int64') label_length = Input(name='label_length', shape=[1], dtype='int64') def ctc_lambda_func(args): y_pred, labels, input_length, label_length = args return K.ctc_batch_cost(labels, y_pred, input_length, label_length) loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([outputs, labels, input_length, label_length]) model = Model(inputs=[inputs, labels, input_length, label_length], outputs=loss_out) |
Compile and Train the Model
To train the model we will use Adam optimizer. Also, we can use Keras callbacks functionality to save the weights of the best model on the basis of validation loss.
|
1 2 3 4 5 |
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer = 'adam') filepath="best_model.hdf5" checkpoint = ModelCheckpoint(filepath=filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='auto') callbacks_list = [checkpoint] |
In model.compile(), you can see that I have only taken y_pred and neglected y_true. This is because I have already taken labels as input to the model earlier.
Now train your model on 135000 training images and 15000 validation images.
|
1 2 3 4 5 6 7 8 9 |
training_img = np.array(training_img) train_input_length = np.array(train_input_length) train_label_length = np.array(train_label_length) valid_img = np.array(valid_img) valid_input_length = np.array(valid_input_length) valid_label_length = np.array(valid_label_length) model.fit(x=[training_img, train_padded_txt, train_input_length, train_label_length], y=np.zeros(135000), batch_size=256, epochs = 100, validation_data = ([valid_img, valid_padded_txt, valid_input_length, valid_label_length], [np.zeros(15000)]), verbose = 1, callbacks = callbacks_list) |
Test the model
Our model is now trained with 135000 images. Now its time to test the model. We can not use our training model because it also requires labels as input and at test time we can not have labels. So to test the model we will use ” act_model ” that we have created earlier which takes only one input: test images.
As our model predicts the probability for each class at each time step, we need to use some transcription function to convert it into actual texts. Here we will use the CTC decoder to get the output text. Let’s see the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# load the saved best model weights act_model.load_weights('best_model_without_thresold.hdf5') # predict outputs on validation images prediction = act_model.predict(valid_img) # use CTC decoder out = K.get_value(K.ctc_decode(prediction, input_length=np.ones(prediction.shape[0])*prediction.shape[1], greedy=True)[0][0]) # see the results i = 0 for x in out: print(valid_orig_txt[i]) for p in x: if int(p) != -1: print(char_list[int(p)], end = '') print('\n') i+=1 |
Here are some results from the trained model:

Pretty good Yeah! Hope you enjoy reading.
If you have any doubt/suggestion please feel free to ask and I will do my best to help or improve myself. Good-bye until next time.
Do you have a full working version of this code on github? It seems some code is missing
hi, yes incase you have github code , let me kno. thank you.
https://github.com/TheAILearner/A-CRNN-model-for-Text-Recognition-in-Keras
Sir, plz share the link your pre trained model and weights
batch_size = 256
epochs = 10
model.fit(x=[training_img, train_padded_txt, train_input_length, train_label_length], y=np.zeros(135000), batch_size=256, epochs = 100,
validation_data = ([valid_img, valid_padded_txt, valid_input_length, valid_label_length], [np.zeros(15000)]), verbose = 1, callbacks = callbacks_list)
ValueError Traceback (most recent call last)
in ()
2 epochs = 10
3 model.fit(x=[training_img, train_padded_txt, train_input_length, train_label_length], y=np.zeros(135000), batch_size=256, epochs = 100,
—-> 4 validation_data = ([valid_img, valid_padded_txt, valid_input_length, valid_label_length], [np.zeros(15000)]), verbose = 1, callbacks = callbacks_list)
2 frames
/usr/local/lib/python3.6/dist-packages/keras/engine/training_utils.py in standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
129 ‘: expected ‘ + names[i] + ‘ to have ‘ +
130 str(len(shape)) + ‘ dimensions, but got array ‘
–> 131 ‘with shape ‘ + str(data_shape))
132 if not check_batch_axis:
133 data_shape = data_shape[1:]
ValueError: Error when checking input: expected input_4 to have 4 dimensions, but got array with shape (0, 1)
How do I change the dimensions to 4?
maybe there is something wrong with this
labels = Input(name=’the_labels’, shape=[max_label_len], dtype=’float32′)input_length = Input(name=’input_length’, shape=[1], dtype=’int64′)
label_length = Input(name=’label_length’, shape=[1], dtype=’int64′)
def ctc_lambda_func(args):
y_pred, labels, input_length, label_length = args
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name=’ctc’)([outputs, labels, input_length, label_length])
#model to be used at training time
model = Model(inputs=[inputs, labels, input_length, label_length], outputs=loss_out)
I don’t know
can you help me?
I want to load my own data
I forked the code
you can see it
this is the error that I get when:
ValueError Traceback (most recent call last)
in
5 batch_size=batch_size, epochs = epochs,
6 validation_data = ([valid_img, valid_padded_txt, valid_input_length, valid_label_length], np.zeros(len(valid_img))),
—-> 7 verbose = 1, callbacks = callbacks_list)
c:\users\yehya\appdata\local\programs\python\python36\lib\site-packages\keras\engine\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, **kwargs)
970 val_x, val_y,
971 sample_weight=val_sample_weight,
–> 972 batch_size=batch_size)
973 if self._uses_dynamic_learning_phase():
974 val_ins = val_x + val_y + val_sample_weights + [0.]
c:\users\yehya\appdata\local\programs\python\python36\lib\site-packages\keras\engine\training.py in _standardize_user_data(self, x, y, sample_weight, class_weight, check_array_lengths, batch_size)
802 ]
803 # Check that all arrays have the same length.
–> 804 check_array_length_consistency(x, y, sample_weights)
805 if self._is_graph_network:
806 # Additional checks to avoid users mistakenly
c:\users\yehya\appdata\local\programs\python\python36\lib\site-packages\keras\engine\training_utils.py in check_array_length_consistency(inputs, targets, weights)
226 raise ValueError(‘All input arrays (x) should have ‘
227 ‘the same number of samples. Got array shapes: ‘ +
–> 228 str([x.shape for x in inputs]))
229 if len(set_y) > 1:
230 raise ValueError(‘All target arrays (y) should have ‘
ValueError: All input arrays (x) should have the same number of samples. Got array shapes: [(4500, 32, 200, 1), (500, 20), (500, 1), (500, 1)]
It can be clearly seen from your error that input size that you are passing to model is varying. You need to be consistent with your input size. Thank you.
thank you sooo much
this time I fixed it
but I have another problem
I cant get the outputs
the predictions are empty
it is []
what is the problem
I train it on an a dataset with 5000 instances
4500 for training
500 for validation
each image is (32,200)
and I have only (lowercase letters)
I have changed every thing needed to changed for my dataset
can you help me please?
do I need a bigger dataset?
Can you check the max length parameter? if that’s outputting the right number of characters
how did you solve this issue?
Actually it is data specific code. I had the same problem but overcome by increase the epochs and decreasing the batch size.
Secondly, I change the architecture of my model for my dataset. As my dataset is so small, total 600 images.
At last, I used RMSPROP optimizers for better accuracy with learning_rate =0.001
if I have images of size 100 by 200, what is the minimal modification of your codes to make it run correctly? I don’t understand the architecture well. thank you very much!
i have padded the images in shape (62, 411, 1) . So when i try to compile the model
” ValueError: Can not squeeze dim[1], expected a dimension of 1, got 2 for ‘lambda_1/Squeeze’ (op: ‘Squeeze’) with input shapes: [?,2,101,512]. ”
this error shows up . How can i solve this ?? Please help me . Thank you !!
If you see in the model architecture code after the conv_7 layer, squeeze function is used. Above used architecture has input size = ( None, 32, 128, 1) which will end up of shape = ( None, 1, 31, 512) after conv_7 layer. That is why I need to squeeze the first dimension.
But in your case if you are using input shape (None, 62,411,1) you are ending up with shape (None, 2, 101, 512). That is why squeeze function is giving an error.
So either you need to change your input size or you can do modification in architecture.
Thanks.
Hey post author!!
Could you please tell me the reason that after the successful training of the model, I am not getting the predicted text
ValueError Traceback (most recent call last)
in ()
3
4 model.fit(x=[training_img, train_padded_txt, train_input_length, train_label_length], y=np.zeros(135000), batch_size=batch_size, epochs = epochs,
—-> 5 validation_data = ([valid_img, valid_padded_txt, valid_input_length, valid_label_length], [np.zeros(15000)]), verbose = 1, callbacks = callbacks_list)
2 frames
/usr/local/lib/python3.6/dist-packages/keras/engine/training_utils.py in standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
129 ‘: expected ‘ + names[i] + ‘ to have ‘ +
130 str(len(shape)) + ‘ dimensions, but got array ‘
–> 131 ‘with shape ‘ + str(data_shape))
132 if not check_batch_axis:
133 data_shape = data_shape[1:]
ValueError: Error when checking input: expected input_1 to have 4 dimensions, but got array with shape (0, 1)
Does it work for low resolution or blurred images as well.
Hi!
I have used this method to detect sentences by increasing the size of input layer.
The problem I am facing is that my sentences are getting truncated,
The system output is not greater than 23 characters,
Can you tell me where I might be going wrong ?
Thanks in advance
hi this code recognition words. Can you recognize sentence ?
This CRNN model is basically created for word recognition. If you want to recognize sentences from text segments, you need to make required changes in the model and train the model according to that. Thanks.
Hi Kang and Atul,
I have a query. How much time it took for you to train the data?
Hi Amir,
So it depends on your GPU configuration. We have trained it on google colab. In the code explained in the blog, we have used batch size of 256 and to train the model for 20 epochs it took around one and half hour.
Thanks
it took 40 hours to train with 32 GB RAM.
Do you have Model Weights Uploaded somewhere?
Hello, I want to perform the same task but for a whole document.
I resized the image and increased the size of input layer. I also made modification in the architecture accordingly but I am stuck with this error for CTC loss:
InvalidArgumentError: 2 root error(s) found.
(0) Invalid argument: Not enough time for target transition sequence (required: 528, available: 31)0You can turn this error into a warning by using the flag ignore_longer_outputs_than_inputs
[[{{node ctc_4/CTCLoss}}]]
(1) Invalid argument: Not enough time for target transition sequence (required: 528, available: 31)0You can turn this error into a warning by using the flag ignore_longer_outputs_than_inputs
[[{{node ctc_4/CTCLoss}}]]
[[training/Adam/gradients/ctc_4/CTCLoss_grad/mul/_461]]
0 successful operations.
0 derived errors ignored.
There is no CTC loss function where I can set the flag to be true.
Please let me know if you have any solution to this.
Also, if you have any other approach for performing OCR on a scanned document, do let me know.
(without Tesseract or any other OCR engines!)
Thanks in advance
Hi!
Can you please explain why have you assigned zeros to y vector in model.fit method? should not y contain the actual labels of training images ?
Thanks in advance!
For the use of CTCModel methods, one recalls that inputs x and y are defined in a particular way as x contains the input observations, the labels, the input lengths and the label lengths while y is a dummy structure. Thus, the fit and evaluate methods require the specific inputs x, while the predict function only requires the observation sequences and observation lengths as input.
as stated in this link : https://www.groundai.com/project/ctcmodel-a-keras-model-for-connectionist-temporal-classification/1
You have displayed the summary of act_model, can you please show the summary of ‘model’?
my dense layer is (None,31,70)
the_labels(Input layer) is (None, 47)
input_length(Input layer) is (None, 1)
label_length (Input layer) is (None, 1)
I got the following error:
sequence_length(0)
Hi,
Thanks for reading this post.
Here is the summary of ‘model’.
Thank You.
while testing it with a new image , is there any pre processing required to be done. thanks !
Hi
Thanks for reading this post. You just need to use same preprocessing steps that are used during training of the model. These steps are convert to grayscale, resize, reshape and normalize.
Excellent post kang & atul .
Do you have the trained model
I tried the same code with same dataset. But I’m not getting the desired loss. Anyway you can help me improve my model ?
It’ll be very helpful, if you can help me complete this.
Change the hyperparameter, like adam to rmsprop.
also increase the epochs and decrease the batch size
i used your script for text recognization of license plate which contain digits + alphabets . however, in output i got alphabets not number.
for example :
acutal label : 7B31231
pred label : B
I have dataset of license plate number images (total images is 600). My valid loss is around 18%.
Can you give any suggestion? What should I do?
In my case, the best val loss is 0.00312 (32971 plate number images in my dateset), maybe you can train the model with more images.
Nice work, which tensorflow version do you use??
Good morning! We are training our OCR for License plate characters on your notebook. Results on valid data are about 80%, on test data results are much lower – about 30-40%. Could you advice on this problem, please. We have no idea how to improve our model. Thank you!
ValueError: Error when checking input: expected input_4 to have 4 dimensions, but got array with shape (3, 1) #16
ValueError Traceback (most recent call last)
in ()
1 batch_size = 256
2 epochs = 1
—-> 3 model.fit(x=[training_img, train_padded_txt, train_input_length, train_label_length], y=np.zeros(len(training_img)), batch_size=batch_size, epochs = epochs, validation_data = ([valid_img, valid_padded_txt, valid_input_length, valid_label_length], [np.zeros(len(valid_img))]), verbose = 1, callbacks = callbacks_list)
2 frames
/usr/local/lib/python3.6/dist-packages/keras/engine/training_utils.py in standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
133 ‘: expected ‘ + names[i] + ‘ to have ‘ +
134 str(len(shape)) + ‘ dimensions, but got array ‘
–> 135 ‘with shape ‘ + str(data_shape))
136 if not check_batch_axis:
137 data_shape = data_shape[1:]
Any reason why this error is occurring and how to solve it?
Hey does this model will work on handwritten letters?